
DDPG(Deep Deterministic Policy Gradient)深度确定性策略梯度算法,是一种强化学习算法。最近在这个算法的原理和应用。
谷歌最早提出这个算法的时候,主要是解决 DQN 算法高维状态空间的问题。DQN 擅长解决的是离散的低维动作空间,而它无法解决高维连续的动作空间。(例如物理控制任务)
DDPG 论文中举了一个例子:一个7个自由度的人类手臂,每个关节粗略的离散化为:{-k, 0, k},那么它的动作空间达到了3^7=2187,这还是粗粒度的情况,若是细粒度的情况,维度会导致维度爆炸。
而在 DQN 的基础上,DDPG 结合了 DQN 的两个优势:1. 从 experience replay buffer 中采用并离线学习样本的相关性;2. 通过一个 Target-Q 网络来提供一致的 TD backup,使用 fixed target 思想。
所以就有了下面这个网友绘制的图,DQN 虽然不能完全算是 Critic 网络,但可以看成如此。对于每个状态下执行的 Action 给出一个 Q-value,最终取最大的 Q-value。而 DDPG 需要同时输入状态和动作,解决连续的动作空间,
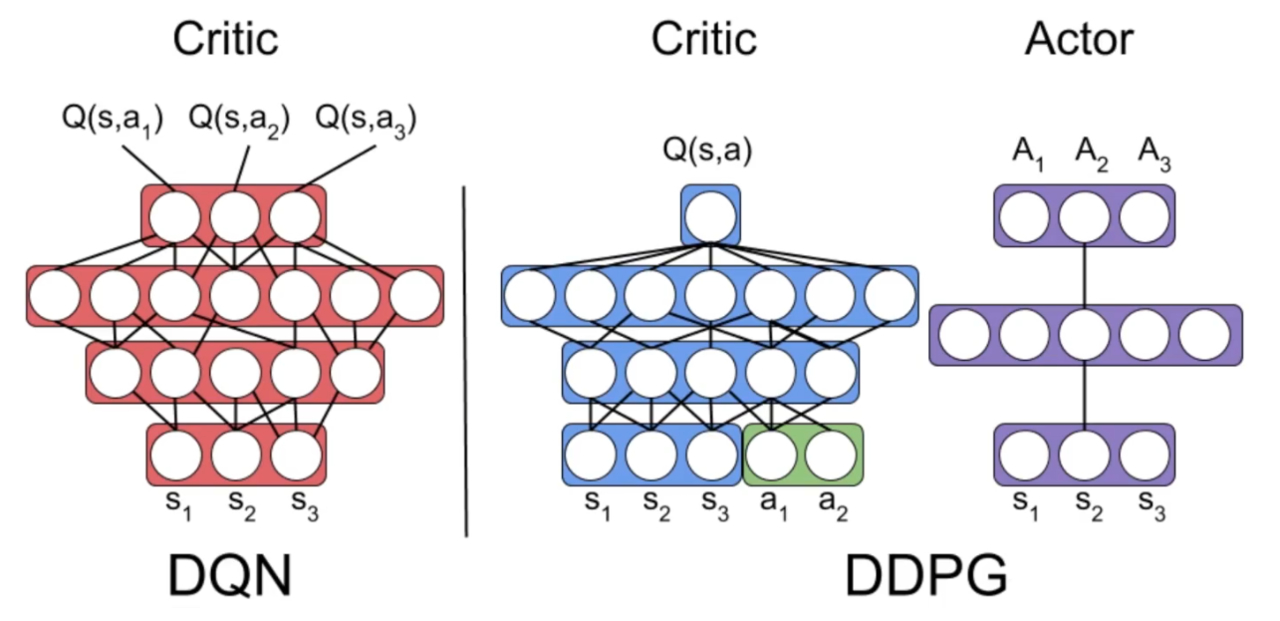
它是有两组 Actor-Critic 网络组成的,顾名思义,Actor——演员,其实就是输出动作的网络,Critic——评论家,则是评判某个状态下动作好坏的网络。
那么四个网络分别的作用如下:
动作价值函数:
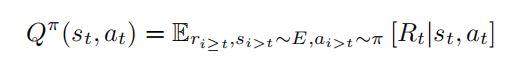
贝尔曼方程:
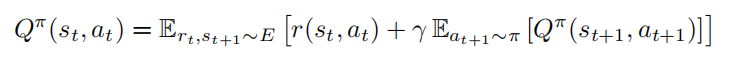
原先的贝尔曼方程输出的是多个动作的概率,由于是确定性策略,需要做的动作只会有一个,所以可以改成一个恒定的 Q值:

Critic 网络的更新,用 off-policy 即可:
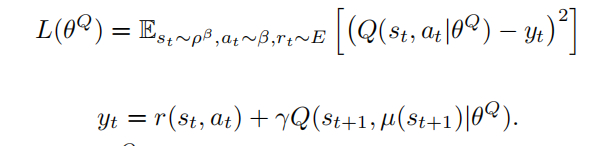
Actor 梯度更新:
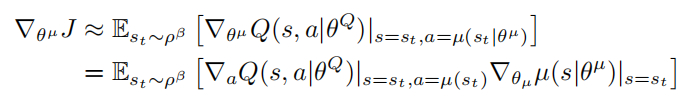
输出动作时增加噪声:
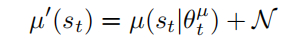
完整的伪代码如下:

训练过程中难免会遇到问题,例如:
解决这些问题查询了许多资料,归结下来有以下几点:
在实用上述解决办法后,都取得了比较满意的效果,有时可能是多种因素造成的问题,需要逐个分析排除,在强化学习的路上愿一帆风顺!!!
 Jeffrey的博客
Jeffrey的博客