
ChatGPT 的出现再次点燃了人工智能学习的热潮,用过的孩子都说好用,事实也确实如此。它的语言理解能力可以说达到了现有人工智能无法到达的高度,应该百分百能通过图灵测试,不仅可以用于日常的交流,甚至还能够编写代码,简单的逻辑处理和模式化工作都能丢给它处理。
ChatGPT (Chat Generative Pre-trained Transformer)从名字就可以看出它实际上是基于 Google 的 Transformer 模型 https://arxiv.org/abs/1706.03762,现在很多的 NLP 应用也都基于该模型开发,之前则是用常规的 RNN 完成。
但天不由人,Google 自己提出的 Transformer,却带火了 Microsoft 的 ChatGPT,如果 ChatGPT 联网对接搜索引擎,那一定会更酷。
不过今天的主角不是 Transformer,而是人工智能的一个重要领域强化学习(Reinforcement Learning),强化学习的主要目的是研究并解决机器人智能体贯序决策问题,有代表性的一个例子就是——AlphaGo 围棋玩得十分六的智能体。
具体的强化学习就不再一一科普了,今天主要是来玩一下强化学习的一个训练场 Gym,没错就是那个开发 ChatGPT 的团队 OpenAI 的另一个作品,Gym 是一个强化学习的训练场,相信已经有很多小伙伴玩过或者听说过这个。
强化学习中,有几个重要的概念,State、Action、Reward、Environment 等,而 Gym 为我们封装好了环境,我们的目的就是使用我们的模型或者称为智能体,对各类游戏进行闯关,以获得最高的 Reward。
跳的有点快哈,由于篇幅有限这里不会具体展开强化学习,Q-Learning 是一种基于值迭代的强化学习算法,用它其实也可以很好的完成上述的游戏的训练了,而我们最终的主角其实不是 Q-Learning,而是 DQN (Deep Q-Learning),它是 Q-Learning 的一种扩展,使用神经网络来估计 Q值,从而可以处理具有高维状态空间的问题(也就是无需再维护复杂的Q表了)
其实 DQN 是属于深度强化学习分支了,也就是说它是由强化学习和深度学习结合而来,这也是我目前在研究的方向。
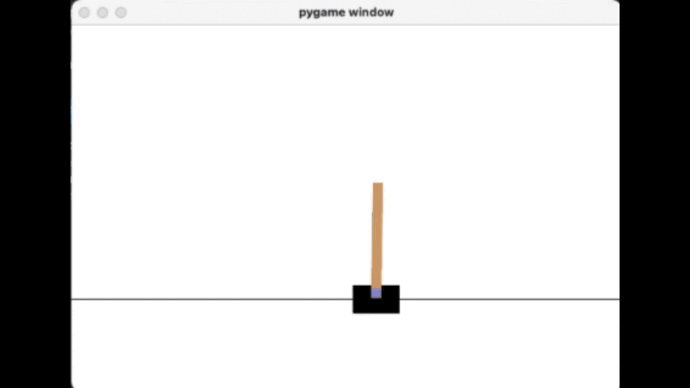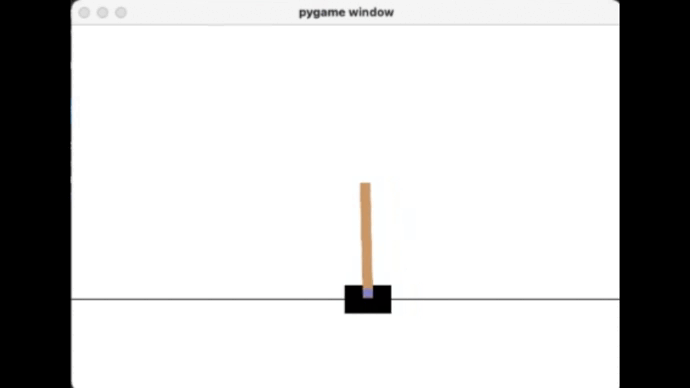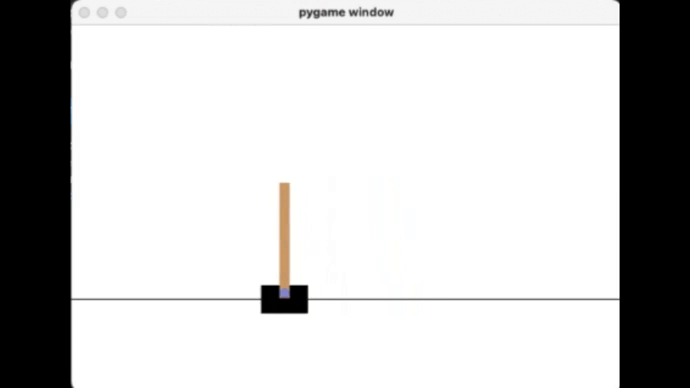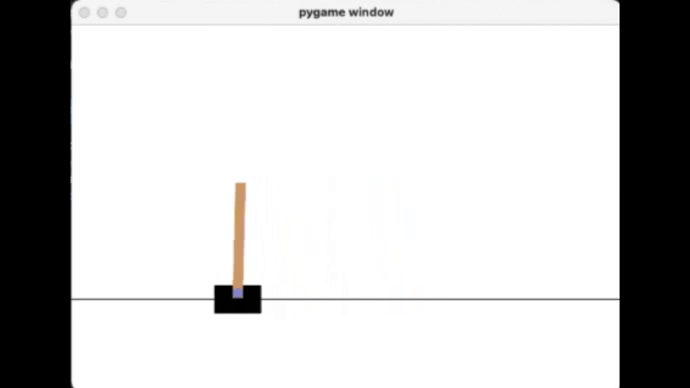
那我们就用 DQN 来玩一下 Gym 中十分经典的一个游戏 Cart Pole ,看着像是一个“锤子”的立杆小车
我们用以下代码让这个锤子动起来,可以根据官方的文档给出的解释得知,这个游戏有两种 Action,分别是0代表向左,1代表向右,我们只要极力控制住这个锤子不翻到,并且不飞出屏幕外就行了。
使用env.action_space.sample()可以随机得到一个动作,observation, reward, done, info, _ = env.step(action)则在完成一个动作后给出了包括 Reward 在内的反馈信息。
import gym
env = gym.make('CartPole-v1', render_mode='human')
env.reset()
for _ in range(1000):
env.render()
action = env.action_space.sample()
observation, reward, done, info, _ = env.step(action)
可以看到运行上面这段程序后,锤子就飞走了,跟个大摆锤似的,很显然,随机的 Action 没法完成我们想要的效果。
那我们还是要请出我们的 DQN 老铁,让它来训训这个不懂事的锤子。
咋们先定义一个简单的神经网络的结构,如下代码这个神经网络中包含了一个全连接层,一个 Relu 线性激活层,和一个输出层。非常的方便哈。
class Net(nn.Module):
def __init__(self, state_size, action_size, hidden_size):
super().__init__()
self.fc = nn.Linear(state_size, hidden_size)
self.out = nn.Linear(hidden_size, action_size)
def forward(self, x):
x = self.fc(x)
x = F.relu(x)
x = self.out(x)
return x
下面就是我要写的 DQN 老铁了,或者称他为智能体。可以看到主要有一个初始化的构造方法,一个选择 Action 的方法,一个更新 Target 网络的方法,一个更新 Epsilon 参数的方法,一个存储经验的方法,还有一个就是让智能体学习变强的方法。
class DQN(object):
def __init__(self, state_size, action_size, hidden_size, lr, batch_size,
epsilon, min_epsilon, epsilon_decay, gamma, memory_size):
pass
def choose_action(self, state):
pass
def update_target_net(self):
pass
def update_epsilon(self):
pass
def store(self, state, action, reward, next_state, done):
pass
def learn(self):
pass
挑几个重要的讲一下,首先是choose_action()选择动作方法,通常他会配合 Epsilon 这个超参数来使用,ε它是做出选择随机动作的概率,1-ε它是选择最优动作的概率,ε=1.0那就表示百分百使用随机函数选择动作,那就不智能了。所以一般 Epsilon 还需要使用update_epsilon()更新,它需要随着训练的加深,逐渐减小,这样能保证刚开始多尝试随机动作,后期选择最优动作。
update_target_net()这个方法可以理解为学习后更新模型参数的方法,它能让模型变得越来越智能,这个方法在后面训练时调用。
store()是一个就经验元组丢进一个队列,这个是一个比较简单的Experience Replay Buffer的实现。
import random
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym
from gym import Env
from collections import deque
class Net(nn.Module):
def __init__(self, state_size, action_size, hidden_size):
super().__init__()
self.fc = nn.Linear(state_size, hidden_size)
self.out = nn.Linear(hidden_size, action_size)
def forward(self, x):
x = self.fc(x)
x = F.relu(x)
x = self.out(x)
return x
class DQN(object):
def __init__(self, state_size, action_size, hidden_size, lr, batch_size,
epsilon, min_epsilon, epsilon_decay, gamma, memory_size):
self.state_size = state_size
self.action_size = action_size
self.hidden_size = hidden_size
self.lr = lr
self.batch_size = batch_size
self.epsilon = epsilon
self.min_epsilon = min_epsilon
self.epsilon_decay = epsilon_decay
self.gamma = gamma
# 经验队列
self.memory = deque(maxlen=memory_size)
self.eval_net = Net(state_size, action_size, hidden_size)
self.target_net = Net(state_size, action_size, hidden_size)
# Adam 算法 https://arxiv.org/pdf/1412.6980.pdf
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=lr)
self.loss_func = nn.MSELoss()
def choose_action(self, state):
if random.uniform(0, 1) >= self.epsilon:
with torch.no_grad():
state = torch.from_numpy(state).float().unsqueeze(0)
q_values = self.eval_net(state)
return torch.argmax(q_values, dim=1).item()
return random.randrange(self.action_size)
def update_target_net(self):
self.target_net.load_state_dict(self.eval_net.state_dict())
def update_epsilon(self):
self.epsilon = max(self.epsilon * self.epsilon_decay, self.min_epsilon)
def store(self, state, action, reward, next_state, done):
experience = (state, action, reward, next_state, done)
self.memory.append(experience)
def learn(self):
batch = random.sample(self.memory, self.batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
states = torch.from_numpy(np.vstack(states)).float()
actions = torch.from_numpy(np.vstack(actions)).long()
rewards = torch.from_numpy(np.vstack(rewards)).float()
next_states = torch.from_numpy(np.vstack(next_states)).float()
dones = torch.from_numpy(np.vstack(dones).astype(np.uint8)).float()
q_value = self.eval_net(states).gather(1, actions)
next_q_value = self.target_net(next_states).detach().max(
1)[0].unsqueeze(1)
target_q_value = rewards + (1 - dones) * self.gamma * next_q_value
loss = self.loss_func(q_value, target_q_value)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss
有了这些其实还不够,我们要让智能体变聪明当然要训练它,所以要有train()方法。
def train(env: Env, agent: DQN, episodes: int):
learn_count = 0
update_cycle = 100
for episode in range(episodes):
# 坑: 一定要取第一个元素 因为第二个元素有时会是空 dict 会导致无法 vstack
state = env.reset()[0]
episode_reward = 0
while True:
action = agent.choose_action(state)
next_state, reward, done, _, _ = env.step(action)
episode_reward += reward
agent.store(state, action, reward, next_state, done)
if len(agent.memory) >= agent.batch_size:
agent.learn()
learn_count += 1
agent.update_epsilon()
if learn_count % update_cycle == 0:
agent.update_target_net()
state = next_state
if done:
break
print(
"Episode: {}/{} | Episode Reward: {:.2f} | Epsilon: {:.2f}".format(
episode + 1, episodes, episode_reward, agent.epsilon))
都到这了,那我把主函数也贴出来吧,这里主要是一些超参数的配置。
if __name__ == '__main__':
env = gym.make('CartPole-v1', render_mode='human')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
hidden_size = 64
lr = 0.01
gamma = 0.95
epsilon = 1.0
min_epsilon = 0.01
epsilon_decay = 0.995
memory_size = 2000
batch_size = 32
episodes = 500
agent = DQN(state_size, action_size, hidden_size, lr, batch_size, epsilon,
min_epsilon, epsilon_decay, gamma, memory_size)
train(env, agent, episodes)
env.close()
可以看到使用训练的模型玩这个游戏,已经不会像之前的大摆锤一样了,但还是有些不稳定。
从图中看到我的 Reward 波动很大,没办法让这个 Reward 一直保持最大化。
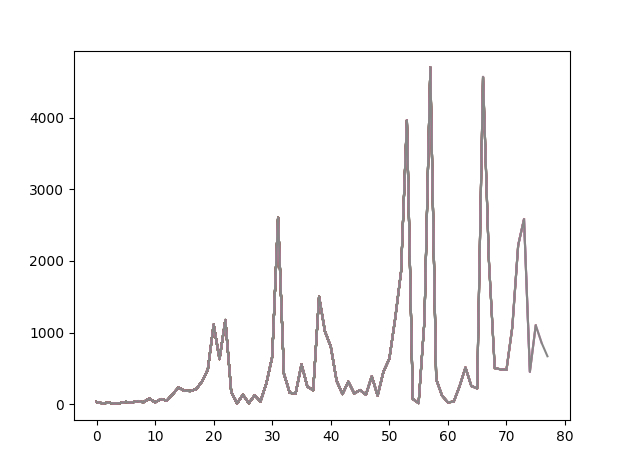
虽然这个模型也能够跑出一万的 Reward,但应该还有优化空间。
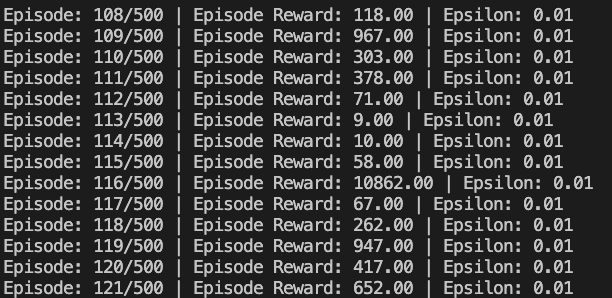
我一直找原因,后来发现网上有博主有另一种计算 Reward 的算法,用它替代后效果有所好转。具体是将agent.store(state, action, reward, next_state, done)中的r3重新计算,使用以下算法。
在至上加入以下代码即可。
n, _, theta, _ = next_state
r1 = (env.x_threshold - abs(n)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
r3 = r1 + r2
可以看到用这种方式计算的 Reward,能让锤子变得更加的稳定坚挺。
而且他看似还做到了 Reward 持续最大化,真像是那么一回事了。
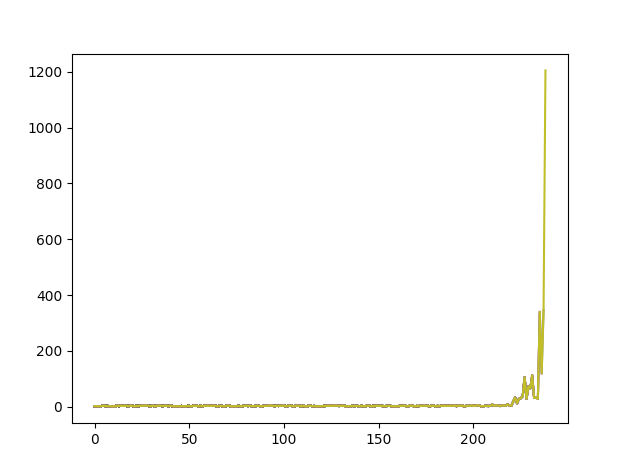
但其实前面很长时间都花在了经验收集上了,所以到了后续出的结果还是和我之前的有些类似,会产生较大的波动。后续将继续深入研究一下这个玩意,想办法让它能够更好的收敛。
 Jeffrey的博客
Jeffrey的博客